현재 댕글 데이터베이스에는 데이터가 약 1,000개 이하로 적은 양이기 때문에 비효율적으로 작성된 쿼리로도 원하는 데이터를 빠른 속도로 가져올 수 있습니다.
하지만 서비스가 성장하면서 데이터 양이 100만 개 혹은 그 이상으로 늘어난다면, 초기에 예상했던 것보다 현저히 느린 조회 속도로 사용자 경험을 저하시키게 되고, 이는 사용자 이탈까지 이어질 수 있습니다.
이러한 문제를 미연에 방지하기 위해, 인프라 확장이나 캐싱 시스템 도입과 같은 복잡한 해결책을 적용하기 전에, 가장 기본적이면서도 효과적인 방법인 SQL 튜닝을 시도해보았습니다.
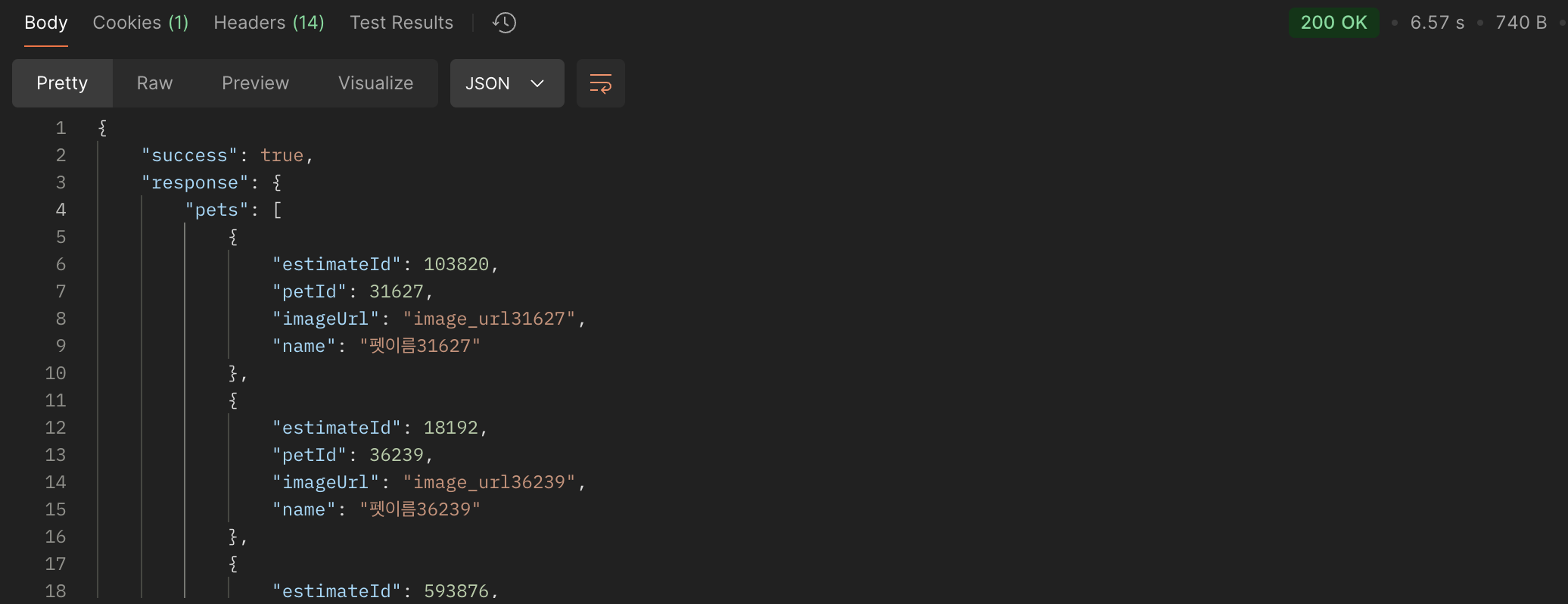
성능 개선 효과를 검증하기 위해 100만 개의 더미 데이터를 데이터베이스에 삽입한 후, 서비스의 주요 기능 중 하나인 “일반 진료 대기 견적서 반려동물 정보 반환 API”에 대한 최적화 전후를 비교해보았습니다.
일반 진료 대기 견적서 반려동물 정보 반환 API (GET)
테스트 환경 : Local MySQL 8.0 / Local 애플리케이션 서버 / 100만 개 데이터 기준
문제 상황
사용자가 요청한 진료 견적서에 대해 병원으로부터 받은 견적서 리스트를 확인하기 전에, 사용자의 반려동물별로 병원에 요청한 견적서가 있는지 확인하기 위한 API로, 사용자가 소유한 모든 반려동물에 대해 견적서 존재 여부를 확인해야 했습니다.
따라서, 사용자가 소유한 반려동물의 수만큼 pet_id 를 변경한 다음 아래의 SQL 문을 수행했습니다.
SELECT * FROM care_estimates
WHERE status = :status AND proposal = :proposal AND pet_id = :pet_id;
한 번의 쿼리 실행에 평균 약 600ms 가 소요되었으며, 이는 데이터양이 증가할수록 더 많은 시간이 필요하게 됩니다.
더 심각한 문제는 이 쿼리가 반려동물 수만큼 반복 실행된다는 점입니다. 예를 들어, 반려동물을 13마리 등록한 사용자의 경우, 약 600ms * 13마리 = 7,800ms = 7.8s 의 시간이 걸리게 됩니다.
웹 사용성 연구에 따르면, 사용자는 일반적으로 2~3초 이상 기다리면 페이지를 이탈할 확률이 크게 증가합니다.
성능 병목 지점 분석
이렇게 느린 쿼리의 원인을 파악하기 위해 MySQL의 쿼리 분석 도구를 활용했습니다.
EXPLAIN을 통한 실행 계획 확인
EXPLAIN 명령을 사용하여 MySQL 옵티마이저가 어떻게 쿼리를 실행하는지 확인했습니다.

여기서 가장 중요하게 봐야되는 것은 type = ALL 입니다.
이는 MySQL이 care_estimates 테이블의 모든 레코드를 처음부터 끝까지 읽는 풀 테이블 스캔을 수행하고 있다는 의미입니다. 100만 개의 데이터를 모두 읽은 후에야 조건에 맞는 레코드를 필터링하는 방식이므로 성능이 저하될 수밖에 없습니다.
또한, possible_keys 와 key 컬럼이 NULL 인 것을 통해 이 쿼리가 어떤 인덱스도 활용하지 못하고 있음을 확인할 수 있습니다.
EXPLAIN ANALYZE를 통한 상세 실행 시간 분석
더 깊이 있는 분석을 위해 MySQL 8.0에서 제공하는 EXPLAIN ANALYZE 명령을 사용했습니다.
이 명령은 쿼리의 각 실행 단계별 소요 시간을 측정할 수 있어 성능 병목 지점을 파악하는 데 매우 유용합니다.
-> Filter: ((care_estimates.pet_id = 31627) and (care_estimates.proposal = 'GENERAL') and (care_estimates.`status` = 'NEW')) (cost=106672 rows=12332) (actual time=94.8..646 rows=1 loops=1)
-> Table scan on care_estimates (cost=106672 rows=986595) (actual time=0.312..618 rows=1e+6 loops=1)- 테이블 스캔 시간 :
care_estimates테이블의 100만 개 레코드를 모두 읽는데618ms가 소요 - 필터링 시간 : 읽은 데이터에서 조건(
pet_id = 31627, proposal = ‘GENERAL’, status = ‘NEW’) 에 맞는 레코드를 찾는 데 추가적으로28ms(646ms - 618ms)가 소요
쿼리 실행 시간의 95% 이상이 테이블 스캔에 소요되고 있었으며, 이 분석을 통해 성능 병목의 주요 원인이 풀 테이블 스캔임을 확인할 수 있었습니다.
따라서 성능 개선을 위해서는 풀 테이블 스캔을 피하고, 필요한 데이터에 빠르게 접근할 수 있는 방법을 찾아야 했습니다.
1. 인덱스 전략을 통한 성능 개선
데이터 특성 및 인덱스 선택 전략
성능 개선을 위해 먼저 쿼리의 WHERE 절에서 사용하는 세 가지 조건(status, proposal, pet_id)의 특성을 비교해봤습니다.
이 중 status 와 proposal 은 데이터 중복도가 pet_id 에 비해 상대적으로 높습니다. (= Cardinality가 낮음)
인덱스 설계 원칙에 따라 세 컬럼 중 pet_id 가 가장 좋은 인덱스 후보임을 알 수 있습니다.
잘못된 인덱스 선택의 예 : status 컬럼 인덱싱
처음에는 status 컬럼에 단일 인덱스를 생성했습니다.
CREATE INDEX estimate_status ON care_estimates(status);
그러나 이 인덱스를 적용한 후 쿼리 실행 시간은 900ms 로 오히려 기존보다 더 느려졌습니다.
상세 실행 시간 분석
원인을 파악하기 위해 다시 EXPLAIN ANALYZE 를 실행했습니다.
-> Filter: ((care_estimates.pet_id = 31627) and (care_estimates.proposal = 'GENERAL')) (cost=24531 rows=23812) (actual time=84.3..858 rows=1 loops=1)
-> Index lookup on care_estimates using estimate_status (status='NEW'), with index condition: (care_estimates.`status` = 'NEW') (cost=24531 rows=476238) (actual time=0.181..850 rows=249998 loops=1)estimate_status라는 인덱스를 사용하여status = 'NEW'조건에 맞는 레코드를 찾음- 이 조건만으로도
249,998개의 레코드가 필터링됨 (전체의 약 25%) - 해당 레코드에 대해 임의 접근(Random I/O)이 발생하며
850ms소요
(status = ‘NEW’조건을 만족하는 데이터가 너무 많아서 인덱스를 사용했음에도 많은 데이터를 읽게 된다. 이때 Random I/O 비용이 발생하는데, 이는 인덱스를 통해 데이터를 찾은 뒤, 각 행에 접근하기 위해 테이블 데이터 페이지를 여러 번 읽어야 하는 비용입니다.) - 추가 필터링 (
pet_id = 31627, proposal = ‘GENERAL’)을 통해 최종적으로 1개 레코드 반환
즉, 인덱스는 많은 레코드를 가리키게 되고, 많은 레코드에 대한 임의 접근이 발생하여 I/O 비용이 증가합니다. 결과적으로 풀 테이블 스캔보다 더 비효율적일 수 있습니다.
status = 'NEW' 는 전체 데이터의 25%를 반환하기 때문에 해당 컬럼에 대한 인덱스는 효율적이지 않습니다.
최종 인덱스 선택 : pet_id 컬럼 인덱싱
앞선 분석을 바탕으로, 카디널리티가 높은 pet_id 컬럼에 인덱스를 적용했습니다.
CREATE INDEX pet_id ON care_estimates(pet_id);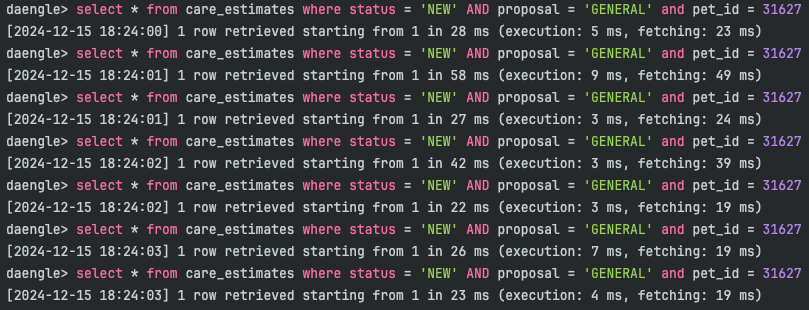
pet_id 를 인덱스 컬럼으로 적용한 후 쿼리를 실행하고 성능을 측정한 결과, 조회 수행 시간이 약 30ms 로 기존 수행 시간(600ms)보다 약 20배 정도의 성능 향상을 보였습니다.
상세 실행 시간 분석
-> Filter: ((care_estimates.proposal = 'GENERAL') and (care_estimates.`status` = 'NEW')) (cost=4.46 rows=0.875) (actual time=0.0544..0.0578 rows=1 loops=1)
-> Index lookup on care_estimates using pet_id (pet_id=31627) (cost=4.46 rows=7) (actual time=0.0486..0.0529 rows=7 loops=1)pet_id인덱스를 사용해pet_id = 31627조건에 맞는 레코드를 찾는 데0.0486ms소요- 인덱스를 통해 단 7개의 레코드만 반환됨
- 소수의 레코드만 메모리에 로드하여 추가 필터링 수행 (
0.0529ms) - 최종적으로 필터링된 결과를 반환하는 데
0.0578ms소요
실제 쿼리 실행 결과, 평균 응답 시간이 30ms 로 측정되어 기존 600ms 대비 95% 단축된 성능을 보여주었습니다.
EXPLAIN ANALYZE 와 실제 쿼리 실행 시간의 차이
EXPALIN ANALYZE에서 측정된 실행 시간은0.0578ms이지만, 실제 쿼리 실행 시간은30ms입니다. 이 차이는 왜 발생하는 것일까요?
실행 계획 측정 시간과 실제 실행 시간의 차이점
1. EXPLAIN ANALYZE 가 측정하는 시간
- 순수한 쿼리 실행 엔진 내부의 처리 시간
- 인덱스 탐색, 데이터 페이지 읽기, 조건 필터링 등의 내부 작업
- 쿼리 파싱이나 최적화 단계는 포함되지 않음
- 결과 집합을 클라이언트로 전송하는 시간 제외
2. 실제 쿼리 실행 시 포함되는 추가 시간
- 쿼리 파싱 및 실행 계획 생성 시간
- 네트워크 통신 지연 시간
- 결과 데이터 전송 시간(fetching)
- 데이터베이스 연결 관리 오버헤드
- 애플리케이션 레벨의 데이터 처리 시간
즉, EXPLAIN ANALYZE 는 DB 서버 내부의 처리 시간을 보여주지만, 실제 실행시에는 클라이언트로 결과를 전송하는 네트워크 시간과 데이터를 가져오는 fetching 시간이 포함됩니다.
[2023-02-15 18:24:00] 1 row retrieved starting from 1 in 28 ms (execution: 5 ms, fetching: 23 ms)
위의 로그에서 보면 총 실행 시간 28ms 중 실제 쿼리 실행에는 5ms 만 소요되고, 결과를 가져오는 데(fetching) 23ms 가 소요되었음을 보여줍니다.
데이터베이스 쿼리 자체의 성능이 좋아도, 네트워크 지연이나 애플리케이션 처리 과정에서 병목이 발생할 수 있기 때문에 성능 최적화 시 전체 응답 시간에 영향을 미치는 모든 요소를 고려해야 합니다.
2. JOIN을 활용한 다중 조회 최적화
지금까지 단일 쿼리의 성능을 개선했지만, 여전히 각 반려동물마다 별도의 쿼리를 실행해야 하는 문제가 있습니다.
- 네트워크 오버헤드 : 반려동물 수만큼 데이터베이스 요청과 응답이 발생
- 연결 관리 비용 : 여러 쿼리를 위한 데이터베이스 연결 관리 리소스 소모
- N+1 문제 : 조회 쿼리가 N번 실행되는 전형적인 N+1 문제
이 문제를 해결하기 위해 JOIN을 활용한 단일 쿼리 접근 방식을 채택했습니다.
JOIN을 활용한 단일 쿼리 방식
SELECT *
FROM care_estimates c
JOIN pets p ON c.pet_id = p.pet_id
WHERE c.user_id = :user_id
AND c.status = :status
AND c.proposal = :proposal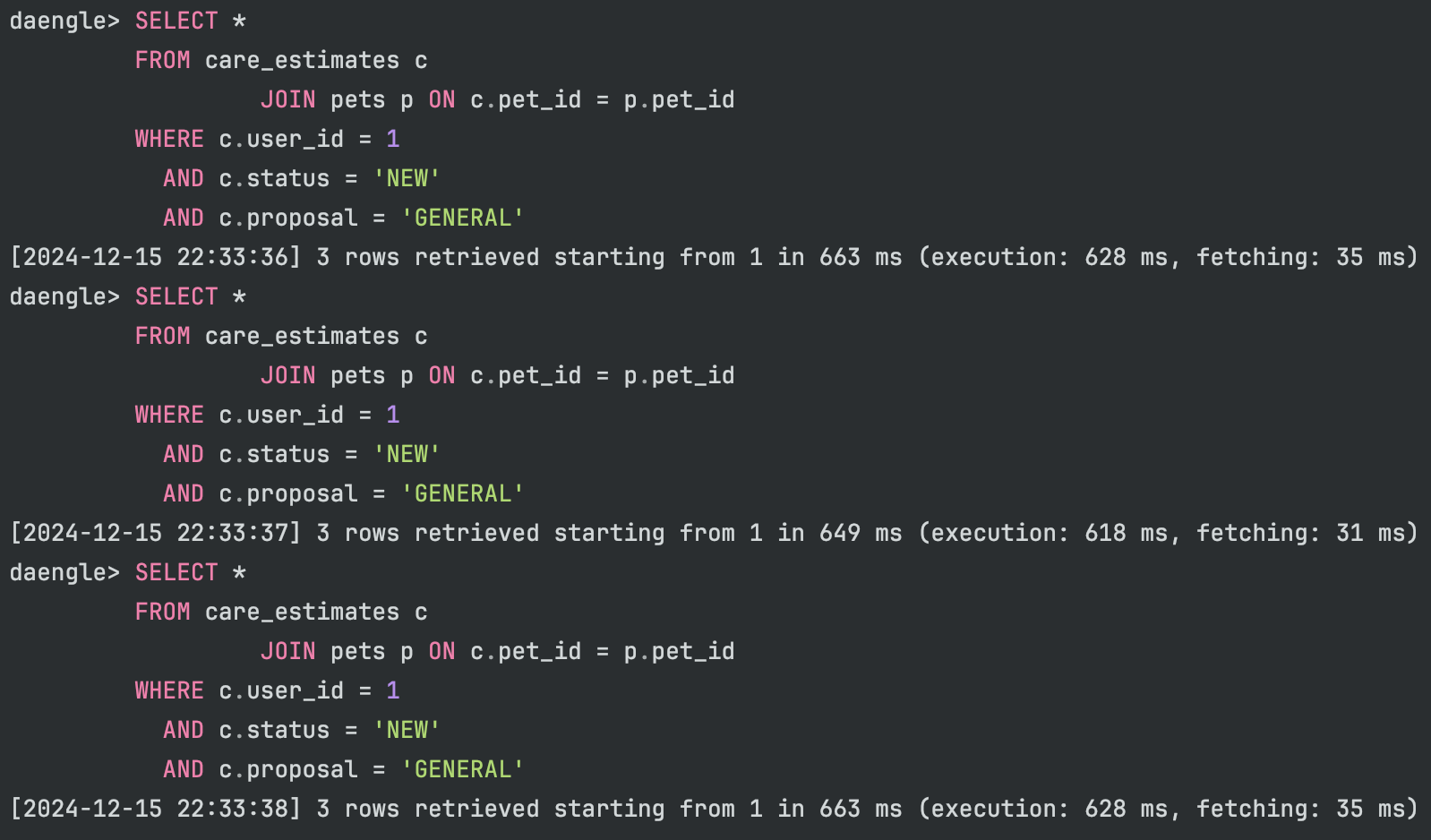
JOIN을 적용한 초기 쿼리의 실행 시간은 약 660ms 로 측정되었습니다. 이는 앞에서 개별 쿼리(30ms) 를 13번 실행하는 것(390ms)보다 느립니다.
실행 계획 확인

실행 계획을 살펴보니 care_estimates 테이블을 풀 스캔하고 있다는 것을 확인했습니다.
상세 실행 시간 분석
조금 더 자세하게 과정별 수행 속도를 분석해 보았습니다.
-> Nested loop inner join (cost=115505 rows=12332) (actual time=154..800 rows=3 loops=1)
-> Filter: ((c.proposal = 'GENERAL') and (c.`status` = 'NEW') and (c.user_id = 1) and (c.pet_id is not null)) (cost=106510 rows=12332) (actual time=154..800 rows=3 loops=1)
-> Table scan on c (cost=106510 rows=986595) (actual time=0.837..708 rows=1e+6 loops=1)
-> Single-row index lookup on p using PRIMARY (pet_id=c.pet_id) (cost=0.629 rows=1) (actual time=0.0325..0.0325 rows=1 loops=3)care_estimates테이블에 대해 적절한 인덱스가 없기 때문에 풀 테이블 스캔이 발생 (708ms)
(WHERE조건에 사용된user_id,status,proposal에 적절한 인덱스가 없기 때문에 풀 테이블 스캔이 발생)WHERE절에 명시된 조건인c.propoal = 'GENERAL',c.status = 'NEW',c.user_id = 1,c.pet_id is not null조건을 통해 필요한 데이터만 남기며 3개의 행을 선택care_estimates에서 필터링된 3개의 행에 대해pets테이블과INNER JOIN을 수행- 총 3번 반복되어서
loop = 3, 0.0325ms * 3 = 0.0975ms가 소요
(pets테이블의 PK를 사용해 단일 행 조회가 효율적으로 수행됨) - Nested Loop Join 방식으로
care_estimates에서 필터링 된 3개의 행에 대해pets테이블을 반복적으로 조회하여 조인 - 그 결과 전체 작업까지 총
800ms소요
성능 저하의 주요 원인은 care_estimates 테이블에서 조건(user_id = 1)에 사용할 수 있는 인덱스가 없어 풀 테이블 스캔이 발생한다는 점입니다.
이전에 생성한 pet_id 인덱스는 WHERE c.pet_id = 특정값 형태의 조건에서만 효과적이며, WHERE c.user_id = 특정값 에서는 활용되지 않습니다.
복합 인덱스를 활용한 성능 개선
JOIN 쿼리의 성능을 향상시키기 위해 user_id 와 pet_id 를 함께 포함하는 복합 인덱스를 생성했습니다.
CREATE INDEX idx_care_estimates_user_pet ON care_estimates (user_id, pet_id);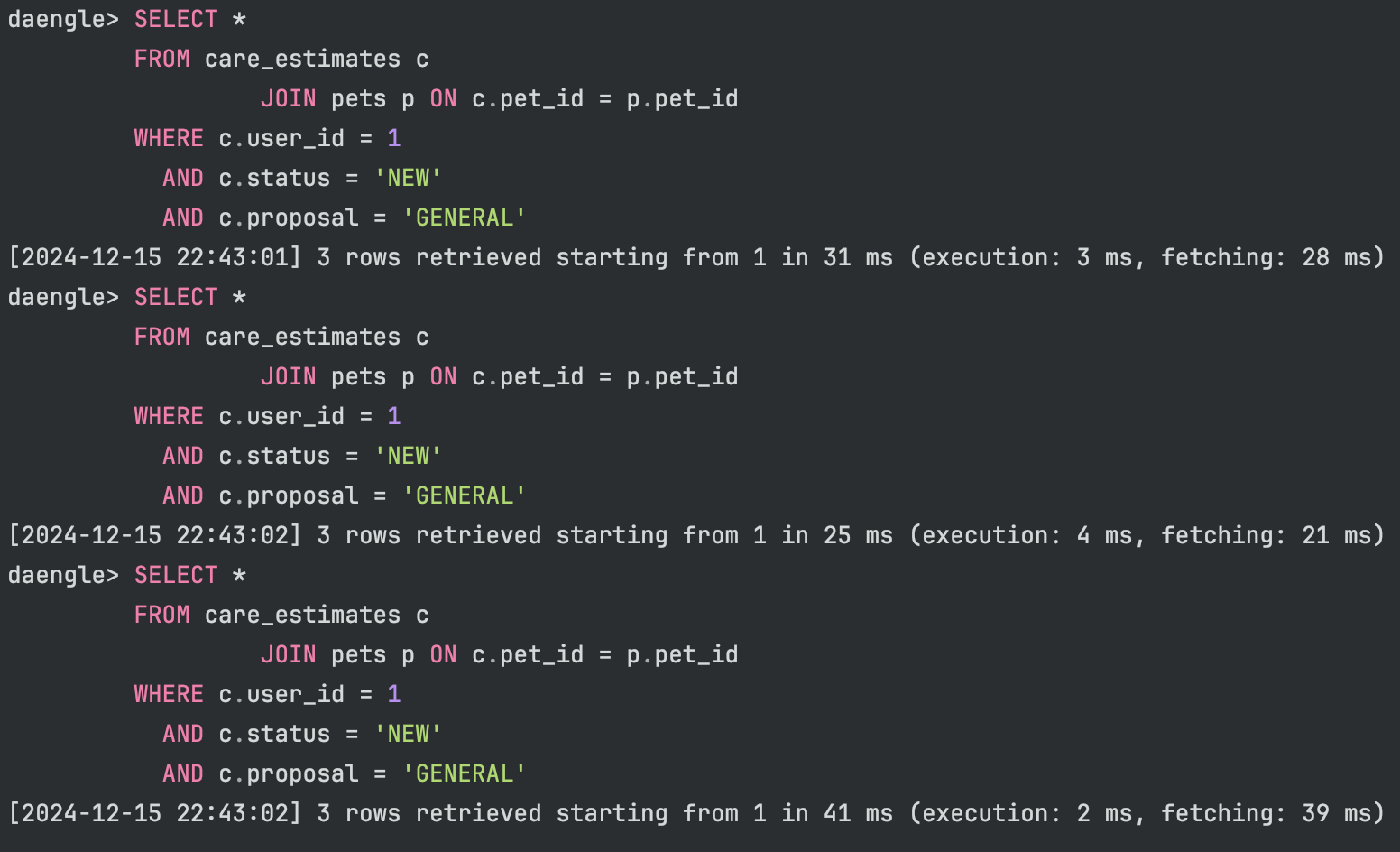
복합 인덱스 적용 후 쿼리 실행 시간은 30ms 로 크게 개선되었습니다.
상세 실행 시간 분석
-> Nested loop inner join (cost=13.9 rows=2) (actual time=0.124..0.142 rows=3 loops=1)
-> Filter: ((c.proposal = 'GENERAL') and (c.`status` = 'NEW')) (cost=12.6 rows=2) (actual time=0.113..0.123 rows=3 loops=1)
-> Index lookup on c using idx_care_estimates_user_pet (user_id=1), with index condition: (c.pet_id is not null) (cost=12.6 rows=16) (actual time=0.106..0.114 rows=16 loops=1)
-> Single-row index lookup on p using PRIMARY (pet_id=c.pet_id) (cost=0.605 rows=1) (actual time=0.00567..0.00571 rows=1 loops=3)- 복합 인덱스
idx_care_estimates_user_pet를 사용해user_id = 1조건에 맞는 16개 행을 찾음 (0.114ms) - 이 16개 행에서
proposal = 'GENERAL', status = 'NEW') 조건으로 추가 필터링하여 3개 행 선택 - 이 3개 행에 대해
pets테이블과 조인 (0.0171ms) - 전체 실행 시간이
0.142ms로 크게 감소
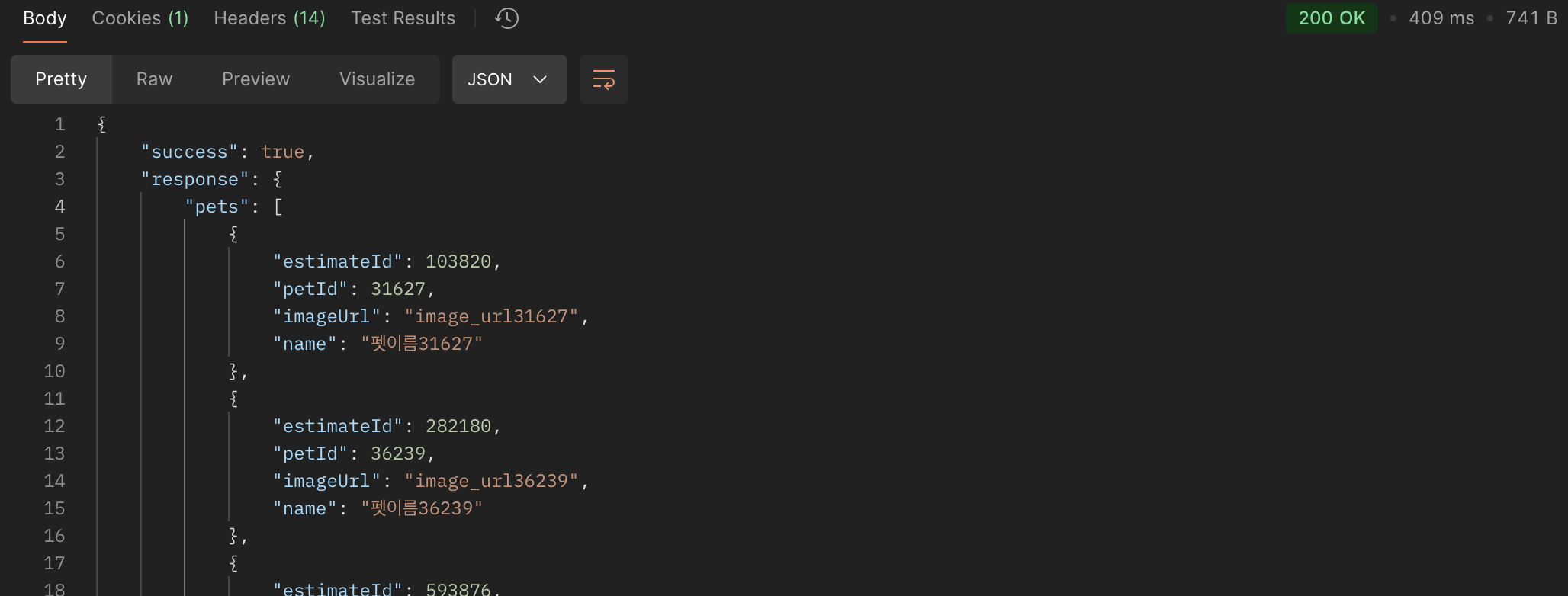
실제 애플리케이션에서 측정한 응답 시간은 30ms 로, 기존 JOIN 방식(660ms) 대비 95% 향상되었습니다.
최종 성능 비교 및 개선 결과
다양한 접근법을 통해 쿼리 성능을 개선한 결과를 비교해 보겠습니다.
특히 사용자가 13마리의 반려동물을 보유한 경우를 가정하여 각 방식의 총 소요 시간을 계산했습니다.
| 최적화 방식 | 수행 시간 (ex. 사용자에게 13마리의 반려동물이 있는 경우) 단일 조회의 경우 반려동물의 수만큼 반복해야 한다. |
실제 애플리케이션 환경 (Postman, Local 환경) |
| 기존 방식 (인덱스 없음, 반려동물별 개별 쿼리) |
646ms * 13 = 8,398ms = 8.3s | 6,570ms = 6.57s |
| pet_id 인덱스 적용 (반려동물별 개별 쿼리) |
30ms * 13 = 390ms = 0.39s | |
| JOIN 활용 (인덱스 없음, 단일 쿼리) |
660ms = 0.66s | |
| 복합 인덱스 + JOIN 활용 (최종 개선) | 30ms = 0.03s | 409ms = 0.409s |
SQL 튜닝 전 코드 (각 반려동물별 개별 쿼리)
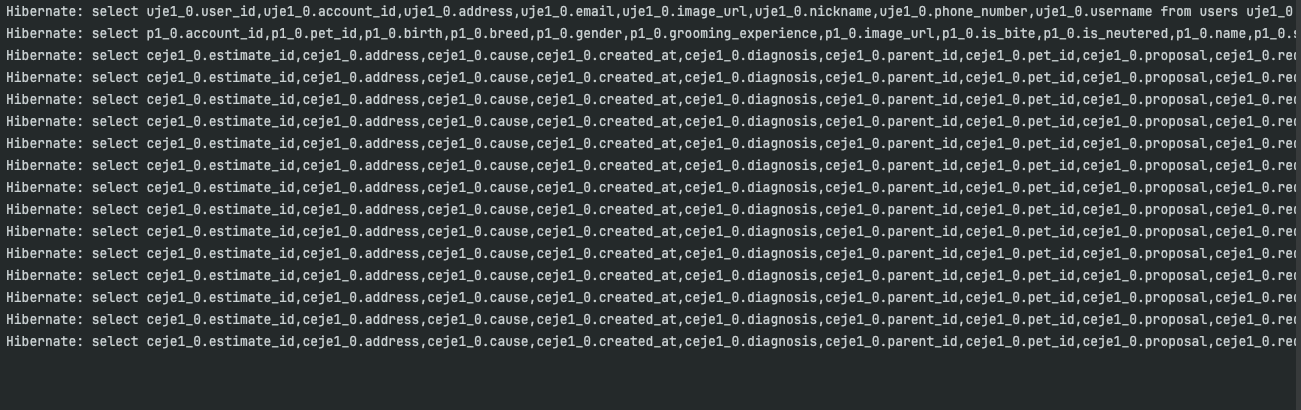
기존 코드에서는 사용자의 모든 반려동물을 조회한 후, 각 반려동물별로 개별 쿼리를 실행하는 방식을 사용했습니다.
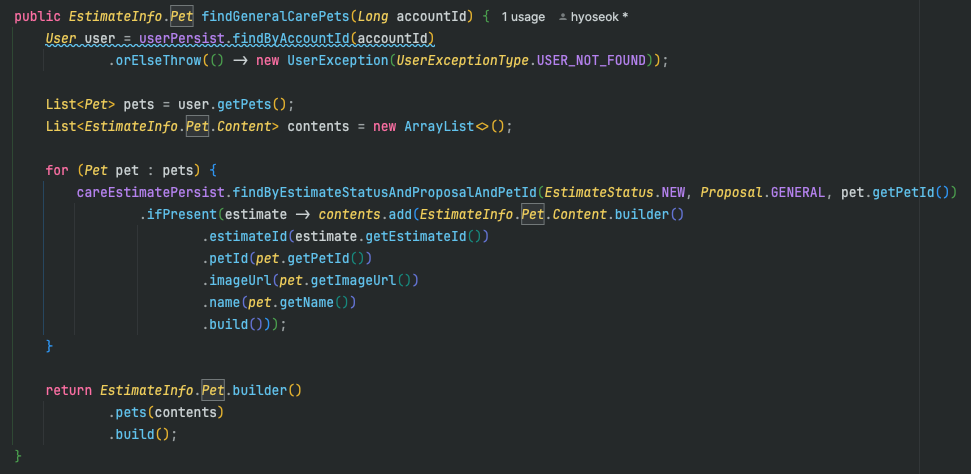

SQL 튜닝 후 코드 (JOIN을 활용한 단일 쿼리)
SQL 튜닝 후에는 JOIN 을 활용한 단일 쿼리로 변경하여 성능을 크게 개선했습니다.



마무리
이번 SQL 튜닝을 통해 기존 6.57s 에서 409ms 로 단축되어 사용자 경험이 크게 향상되었으며, 향후 데이터가 더 증가하더라도 안정적인 성능을 유지할 수 있게 되었습니다.
다음 편에서는 대기 진료 견적서 상세 조회 API에 대한 성능 최적화 과정에 대해 작성하겠습니다.
SQL 튜닝을 통한 API 성능 최적화 (2편)
SQL 튜닝을 통한 API 성능 최적화 (1편)현재 댕글 데이터베이스에는 데이터가 약 1,000개 이하로 적은 양이기 때문에 비효율적으로 작성된 쿼리로도 원하는 데이터를 빠른 속도로 가져올 수 있습니
hyodeng.tistory.com
'프로젝트' 카테고리의 다른 글
| SQL 튜닝을 통한 API 성능 최적화 (2편) (0) | 2025.03.11 |
|---|---|
| 성장하는 서비스를 위한 DDD 기반 멀티 모듈 전환기 (0) | 2025.03.07 |
| Spring MVC의 진입점을 파고들어 개선한 JWT 토큰 처리 시스템 (0) | 2025.02.19 |
| Spring Boot + MySQL로 구현한 선착순 이벤트 시스템 (1편) (0) | 2025.02.09 |
| JPA와 MySQL로 구현한 동시성 (0) | 2025.02.05 |