

“매일 오후 1시에 선착순 100명에게 도서를 증정하는 이벤트 시스템”을 개발하게 되었습니다.
처음엔 단순해 보였지만, 높은 동시성과 정확성이 요구되는 이 과제는 생각보다 많은 도전 과제를 안겨주었습니다.
이 글에서는 Spring Boot와 MySQL만으로 시작해 어떤 문제에 직면했고, 어떻게 이를 분석하고 개선해 나갔는지 경험을 공유하고자 합니다.
요구사항 분석
프로젝트 시작 시 다음과 같은 요구사항을 확인했습니다.
- 매일 오후 1시에 선착순 100명 한정 이벤트 진행
- 1분에 10만 건의 요청을 10분간 처리 (초당 약 1,666건)
- 중복 응모 방지
- 정확히 100명까지만 선발
- 다음날 오후 1시에 당첨자 발표
가장 핵심적인 요구사항은 초당 1,666건의 요청 중에서 정확히 100명만 선발하고, 동일 사용자의 중복 응모를 방지하는 것이었습니다.
이벤트 당첨 여부를 실시간으로 사용자에게 알려줄 필요는 없었으므로 이벤트 응모의 정확성과 시스템 안정성에 초점을 맞추기로 했습니다.
초기 아키텍처 선택
가장 기본적인 형태로 시스템을 구현하기 위해 Spring Boot와 MySQL만을 사용한 단일 서버 구조로 시작했습니다.
복잡한 시스템을 한번에 구축하기보다는 기본 구조에서 시작해 실제 문제가 발생하는 지점을 파악하고 점진적으로 개선해 나가는 방식이 더 효율적이라 판단했습니다.
초기 핵심 도메인 모델 설계
응모 도메인
응모 이벤트의 핵심 도메인 모델로 Apply 엔티티를 설계했습니다.
@Entity
@Getter
@NoArgsConstructor
public class Apply {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String phoneNumber;
private long applyTime;
@Builder
public Apply(String name, String phoneNumber, long applyTime) {
this.name = name;
this.phoneNumber = phoneNumber;
this.applyTime = applyTime;
}
}name: 응모자 이름phoneNumber: 응모자 전화번호 (중복 응모 체크 용도)applyTime: 응모 시간 (타임스탬프)
핵심 비즈니스 로직
이벤트 응모 처리를 위한 핵심 비즈니스 로직은 아래와 같이 구현했습니다.
@Transactional
public String apply(ApplyRequestDto requestDto) {
// 중복 응모 체크
if (applyRepository.existsByPhoneNumber(requestDto.getPhoneNumber())) {
throw new ApiException(ErrorCode.DUPLICATE_APPLY);
}
// 응모 데이터 저장
Apply apply = Apply.builder()
.name(requestDto.getName())
.phoneNumber(requestDto.getPhoneNumber())
.applyTime(requestDto.getApplyTime())
.build();
applyRepository.save(apply);
return "응모가 성공적으로 등록되었습니다.";
}- 중복 응모 체크 : 동일한 전화번호로 이미 응모했는지 확인하여 중복 응모를 방지합니다.
- 응모 정보 저장 : 중복 체크를 통과한 응모 정보를 데이터베이스에 저장합니다.
하지만, 위 구현만으로는 심각한 문제점들이 있었고 이를 하나씩 발견하고 해결해나갔습니다.
초기 구현에서의 문제점 및 고민
처음에는 “서버에 먼저 도착한 요청이 먼저 처리된다.”라고 생각했지만, 실제 운영 환경에서는 이 가정이 성립하지 않는 상황을 발견했습니다.
1. 요청 처리 순서와 선착순 판정의 문제
Spring Boot의 멀티스레드 환경에서는 서버에 도착한 요청 순서와 실제 처리 순서가 반드시 일치하지 않는 현상이 발생했습니다.
이는 선착순 이벤트의 공정성에 문제를 가져왔습니다.

- 요청 A가 요청 B보다 먼저 서버에 도착 (A: 13:00:01.235, B: 13:00:01.458)
- 서버의 멀티스레드 환경에서 스레드 스케줄링에 따라 요청 B가 먼저 처리를 시작
- 데이터베이스 연결 풀에서 요청 B가 먼저 커넥션을 획득
- 요청 B가 먼저 데이터베이스에 저장됨 (이 시점의 응모자 순위는 B가 A보다 앞섬)
- 이후 요청 A가 처리됨 (그러나 A는 B보다 실제로 먼저 도착함)
이러한 시나리오에서 “선착순”의 의미가 모호해집니다. 실제로 먼저 요청한 사용자(A)가 아닌, 처리 속도가 빠른 요청(B)이 우선권을 갖게 되어 공정성 문제가 발생합니다.
이 문제를 해결하기 위해 초기 단계에서는 요청 접수 즉시 타임스탬프를 기록하고 이후 배치 작업을 통해 시간순으로 정렬하여 상위 100명을 선정하는 방식이 가장 공정하고 기술적으로 실현 가능하다고 판단했습니다.
2. 클라이언트 시간 의존 문제
초기 구현에서는 클라이언트가 전송한 applyTime 을 그대로 사용했습니다.
Apply apply = Apply.builder()
.name(requestDto.getName())
.phoneNumber(requestDto.getPhoneNumber())
.applyTime(requestDto.getApplyTime()) // 클라이언트 시간 사용
.build();이로 인해 여러 문제점이 발생했습니다.
- 시간 변조 가능성 : 악의적인 사용자가 자신의 요청 시간을 조작하여 실제보다 빠른 시간으로 설정함으로써 선착순에서 우위를 차지할 수 있습니다.
- 클라이언트 시간 불일치 : 사용자 기기의 시간 설정이 정확하지 않을 수 있음
- 공정성 문제 : 네트워크 지연이 발생하는 경우, 실제로 먼저 버튼을 누른 사용자의 요청이 서버에 늦게 도착할 수 있습니다.
이러한 문제를 검토한 결과, "선착순"의 정의를 "서버에 먼저 도착한 요청"으로 재정의하는 것이 타당하다고 판단했습니다.
다양한 대안을 검토했지만,
- 토큰 기반 방식: 사용자에게 미리 토큰을 발급하고, 이벤트 시작 시 토큰 사용 순서로 선착순 결정
- 예약 시스템: 이벤트 시작 전에 사전 예약을 받고, 예약 시간 순으로 처리
- 대기열 시스템: 모든 요청을 대기열에 넣고 선입선출(FIFO) 방식으로 처리
이번 요구사항에서는 "선착순 100명"이라는 명확한 조건이 있었기 때문에 서버 도착 시간을 기준으로 하는 것이 가장 객관적이고 측정 가능한 방식이라고 판단했습니다.
따라서 서버 시간을 사용하도록 코드를 수정했습니다.
// 서버에서 현재 시간 측정
long currentServerTime = System.currentTimeMillis();
Apply apply = Apply.builder()
.name(requestDto.getName())
.phoneNumber(requestDto.getPhoneNumber())
.applyTime(currentServerTime) // 서버 시간 사용
.build();이렇게 변경함으로써 사용자 간 공정한 경쟁 환경을 조성하고 시간 변조 시도를 원천적으로 차단할 수 있게 했습니다.
3. 중복 체크와 데이터 저장의 간극으로 인한 동시성 문제
초당 1,666개의 요청이 발생하는 환경에서 중복 체크 로직에 동시성 문제가 발생했습니다.


- 스레드 A : 전화번호 “010-1234-5678” 중복 체크 → DB에 해당 전화번호 없음 확인
- 스레드 B : 같은 시점에 동일 전화번호 중복 체크 → DB에 없음 (아직 A가 저장하지 않았으므로)
- 스레드 A : DB에 응모 정보 저장
- 스레드 B : DB에 응모 정보 저장 (중복 데이터 발생)
이는 ‘Time of Check to Time of Use’ 문제로 검사 시점(중복 체크)과 사용 시점(데이터 저장) 사이의 시간 간격 동안 다른 트랜잭션이 개입하여 상태를 변경할 수 있기 때문에 발생하는 동시성 이슈입니다.
동시성 문제 해결 방안 고민
동시성 문제를 해결하기 위해 다양한 접근 방식을 검토했습니다.
- 유니크 인덱스 활용
- 장점 : 데이터베이스 수준에서 중복을 확실하게 방지할 수 있으며, 별도의 중복 체크 로직이 불필요
- 단점 : 고부하 상황에서 많은 중복 키 예외가 발생하면 예외 처리 로직으로 인한 성능 저하 가능성이 높음
- 낙관적 락(Optimistic Lock)
- 장점 : 락 획득을 위한 대기 시간이 없어 일반적인 상황에서 처리량이 높음
- 단점 : 동시성이 높은 환경에서는 충돌 빈도가 증가하여 재시도 로직 실행이 급증하므로 성능이 저하될 수 있음
- 비관적 락(Pessimistic Lock)
- 장점 : 트랜잭션 격리를 통해 동시성 문제를 근본적으로 해결하고 일관성을 보장
- 단점 : 락 획득 과정에서 대기 시간이 발생하여 전체 처리량 감소 가능성
각 방식의 특성을 분석한 결과 데이터 정확성이 가장 중요한 선착순 이벤트 선착순 이벤트에서는 비관적 락을 적용하는 것이 가장 적합하다고 판단했고 비록 성능 면에서 단점이 있지만 중복 응모를 완벽하게 방지하는 것이 최우선 요구사항이라고 생각했습니다.
이를 통해 동일한 전화번호로 동시에 요청이 들어오더라도 한 번에 하나의 요청만 처리되도록 구현했습니다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
boolean existsByPhoneNumber(String phoneNumber);
MySQL InnoDB의 트랜잭션 락 메커니즘 이해
비관적 락 구현 후 중복 응모 문제는 해결되었지만 “쿼리가 끝나면 락이 해제되는데 어떻게 중복이 방지되지?”라는 의문이 생겼고 해당 메커니즘이 어떻게 동작하는지 이해할 필요가 있었습니다.
- 트랜잭션 범위의 락 유지
@Transactional어노테이션으로 묶인 메서드 내에서 획득한 비관적 락은 단순히 쿼리 실행 중에만 유지되는 것이 아니라 트랜잭션이 완전히 종료될 때까지(commit 또는 rollback) 유지됩니다.- 이는 기존 쿼리가 종료된 이후에도 INSERT, UPDATE 등의 후속 작업 중에 다른 트랜잭션이 간섭하지 못하도록 보장합니다.
- Next-Key 락의 동작
- InnoDB는 기본적으로 REPEATABLE READ 격리 수준에서 작동하며, 이 수준에서
SELECT ... FOR UPDATE쿼리는 Next-Key 락을 사용합니다. - Next-Key 락은 인덱스 레코드 락(Index Record Lock)과 갭 락(Gap Lock)의 조합으로, 검색 조건에 해당하는 인덱스 레코드뿐만 아니라 ‘인접 갭’까지 잠금 범위에 포함시킵니다.
- InnoDB는 기본적으로 REPEATABLE READ 격리 수준에서 작동하며, 이 수준에서
- Phantom Read 방지
- Next-Key 락의 핵심 기능 중 하나는 팬텀 읽기(Phantom Read) 문제를 방지하는 것입니다.
- 팬텀 읽기란 트랜잭션 실행 중에 다른 트랜잭션이 새 행을 삽입해 이전에 없던 레코드가 나타나는 현상입니다.
- Next-Key 락은 이러한 삽입을 물리적으로 차단하여 트랜잭션의 일관된 뷰를 보장합니다.
인덱스와 락 범위의 관계
여기서 중요한 점은 인덱스의 존재 여부가 락의 범위에 결정적인 영향을 미친다는 것입니다.
- 인덱스가 있는 경우
- 지정된 전화번호에 대한 Next-Key 락만 획득됩니다.
- 이 락은 해당 전화번호 레코드(이미 존재하는 경우) 또는 해당 전화번호가 위치할 갭에만 적용됩니다.
- 다른 전화번호에 대한 쿼리는 독립적으로 처리될 수 있어 병렬 처리가 가능합니다.
- 인덱스가 없는 경우
WHERE phoneNumber = '010-1234-5678'조건을 확인하기 위해 테이블 전체 스캔이 필요합니다.- 이 과정에서 접근하는 모든 레코드에 락이 걸리게 됩니다.
- 이는 공식적인 테이블 락은 아니지만, 실질적으로 테이블 락과 유사한 효과를 가져옵니다.
- 따라서 다른 전화번호로 접근하는 트랜잭션도 대기 상태에 놓이게 됩니다.
중복 방지 메커니즘의 실제 동작 과정
JPA와 Hibernate를 사용할 때 @Lock(LockModeType.PESSIMISTIC_WRITE) 를 적용한 쿼리는 MySQL에서 내부적으로 아래와 같은 SQL 구문으로 변환됩니다.
SELECT * FROM Apply WHERE phoneNumber = '010-1234-5678' FOR UPDATE이 쿼리가 실행되면, 다음과 같은 단계로 중복 방지가 이루어집니다.

트랜잭션 A 시작
- SELECT * FROM Apply WHERE phoneNumber = '010-1234-5678' FOR UPDATE
- 결과: 0 (존재하지 않음)
- 이 시점에 phoneNumber '010-1234-5678'에 대한 Next-Key 락 획득
- INSERT INTO Apply VALUES (...) 실행
트랜잭션 A 커밋
- 락 해제
동시에 트랜잭션 B 시작
- SELECT * FROM Apply WHERE phoneNumber = '010-1234-5678' FOR UPDATE
- 이 쿼리는 트랜잭션 A가 획득한 락 때문에 대기
- 트랜잭션 A가 커밋된 후에야 실행 가능
- 이 시점에서는 이미 레코드가 존재하므로 중복 체크에서 걸림
- 예외 발생 또는 조건 분기에 따른 처리
트랜잭션 B 커밋 또는 롤백이러한 락 메커니즘을 통해 중복 응모 문제를 효과적으로 해결할 수 있었습니다. 그러나 비관적 락 방식은 높은 동시성이 요구되는 환경에서는 새로운 성능 도전 과제를 가져왔습니다. 특히 락 경합(Lock contention)이 심해지면서 전체 시스템 처리량이 감소하는 현상이 관찰되었습니다.
4. 응모 수 제한을 통한 최적화
비관적 락의 적용으로 이전에 문제가 되었던 스레드 스케줄링에 의한 처리 순서 예측 불가능 문제가 해결되었습니다.
비관적 락은 트랜잭션 간의 경쟁 조건을 제거하고 요청을 순차적으로 처리하게 만들었습니다.
이로 인해 모든 응모 요청을 무조건 DB에 저장한 후 나중에 정렬하는 과정이 필요 없어졌습니다.
새로운 접근법으로 직렬화된 처리에 응모 개수 제한을 추가하여 시스템을 최적화했습니다.
@Transactional
public String apply(ApplyRequestDto requestDto) {
// 중복 응모 체크
if (applyRepository.existsByPhoneNumber(requestDto.getPhoneNumber())) {
throw new ApiException(ErrorCode.DUPLICATE_APPLY);
}
// 응모 수 체크
long count = applyRepository.count();
if (count >= 100) {
throw new ApiException(ErrorCode.APPLY_LIMIT_EXCEEDED);
}
// 서버 시간 측정
long currentServerTime = System.currentTimeMillis();
// 응모 데이터 저장
Apply apply = Apply.builder()
.name(requestDto.getName())
.phoneNumber(requestDto.getPhoneNumber())
.applyTime(currentServerTime)
.build();
applyRepository.save(apply);
return "SUCCESS";
}저는 phoneNumber 필드에 인덱스를 생성하지 않았기 때문에 apply 테이블 전체에 락이 걸리는 효과가 발생하고 이로 인해 count() 메서드 호출의 동시성 문제 또한 발생하지 않습니다.
만약 phoneNumber 에 인덱스가 있었다면
- 각 전화번호별로 락이 독립적으로 적용
- 서로 다른 전화번호로 동시에 응모한 요청들이 병렬 처리
- 같은 시점에 여러 트랜잭션이
count() < 100을 확인하고 동시에 데이터 저장 가능 - 결과적으로 100명 이상의 당첨자가 선정될 가능성이 있음
인덱스가 없는 상황
- 전체 테이블에 락이 걸림
- 모든 트랜잭션이 직렬화되어 처리
- 한 트랜잭션이
count()를 호출하고 데이터를 저장할 때까지 다른 트랜잭션은 대기 - 정확히 100명만 선정되는 결과를 얻을 수 있음
이러한 최적화에도 불구하고 비관적 락 기반의 직렬화된 처리 방식은 모든 요청을 순차적으로 처리하기 때문에 여전히 성능 제약을 가지고 있었습니다.
성능 테스트 및 모니터링 설정
Spring Boot + MySQL, 로컬 단일 서버 환경
대용량 트래픽 상황에서 시스템이 어떻게 동작하는지, 어디서 병목이 생기는지 직접 경험해보는 것이 중요하다고 판단했습니다.
따라서 선착순 100명만 선발해야 하는 시스템을 개발하면서 초당 1,666건의 트래픽을 처리할 수 있을지 확인하기 위해 성능 테스트와 모니터링 환경을 구축했습니다.
테스트 환경 구성
- 테스트 도구 : K6
- 모니터링 : Prometheus, Grafana
- 테스트 시나리오 : 초당 1,000건의 요청을 10분간 전송
성능 테스트를 통해 시스템의 한계를 확인하고 병목 지점을 찾아내는 과정이 필요했습니다. 단순히 도구를 사용해보는 것이 아니라, 실제 대용량 트래픽 상황을 시뮬레이션하고 문제를 발견하며 해결책을 찾는 경험을 쌓고자 했습니다.
성능 테스트 결과 분석
테스트 결과, 시스템이 목표했던 초당 1,666건의 요청을 처리하지 못하고 1,000 RPS 정도에서도 한계를 보였습니다.
요구사항을 충족시키지 못하는 수준이었지만, 단순히 ‘성능이 부족하다’는 결론에서 그치지 않고, 정확히 어떤 부분이 병목이 되는지 각 요소별로 상세 분석을 진행했습니다.
JVM 메모리 및 GC 분석
JVM 메모리와 GC 패턴 분석으로 Java 애플리케이션의 성능 병목을 파악했습니다.
Eden Space 사용 패턴

메모리 모니터링 결과, Eden Space 사용량이 10MB~40MB 사이에서 불안정하게 변동했습니다.
이는 아래와 같은 객체들이 빈번하게 생성되고 소멸되는 것을 의미합니다.
ApplyRequestDto, ResponseDto객체 : API 요청마다 생성되는 DTO 객체- JPA 영속성 컨텍스트 관련 객체 : 엔티티 객체, 쿼리 실행 관련 객체
- DB 쿼리 실행 관련 임시 객체 : JDBC 연결 객체
G1 GC 동작 패턴

G1 GC 로그 분석 결과
- GC 빈도 : 평균 초당 0.458회의 Minor GC 발생 (약 2.2초당 1회)
- Stop-The-World 시간 : Minor GC당 평균 4.57ms, 최대 11.6ms의 Stop-the-World(STW) 발생
가장 중요한 지표는 최대 11.6ms의 STW 시간입니다. 이론적으로 1,666 RPS 환경에서 각 요청의 최대 허용 처리 시간은 0.6ms 입니다.
하나의 응모 요청당 평균 처리 시간 = 1,000ms/1,666 ≈ 0.6ms따라서 11.6ms의 STW는 약 19.3개 요청의 처리가 지연된다는 의미입니다.
STW(11.6ms)동안 처리되지 못하는 요청 = 11.6/0.6 ≈ 19.3개더 심각한 문제는 실제 1,666 RPS 환경에서는 메모리 할당률 증가로 인해 GC 빈도와 STW 시간이 지금보다 더 증가할 가능성이 높다는 점입니다.
Thread Pool 분석
Tomcat의 기본 스레드 풀 크기는 400개로 설정되어 있었습니다.

- 스레드 상태 : 대부분의 스레드가 WAITING 또는 BLOCKED 상태에 있음
- 스레드 포화 영향 : 400개 스레드가 모두 사용 중일 때 추가 요청은 Tomcat의 요청 큐에서 대기하게 되며, 큐 포화 시 connection refused 오류 발생
특히 요청 처리 시간(Requests Duration)이 시간이 지남에 따라 급격히 증가하고 있습니다.
- 평균 처리 시간 : 초기 0.1ms 미만에서 점차 증가하여 약 0.433ms까지 상승
- 최대 처리 시간 : 테스트 후반부에는 3.44ms까지 상승
스레드 라이프사이클 상세 분석
- HTTP 요청 접수 : 클라이언트로부터 요청 수신
- 스레드 할당 : Tomcat 스레드 풀에서 가용 스레드 할당
- DB 작업 수행 (블로킹 발생)
- DB 커넥션 획득 대기
- 데이터베이스 락 획득 대기
- 쿼리 실행 및 결과 대기
- 응답 반환 및 스레드 반납 : 작업 완료 후 스레드 풀로 반환
핵심 문제는 스레드 자체가 부족한 것이 아니라 대부분의 스레드가 DB 관련 작업을 위해 블로킹되어 있다는 점입니다. 400개 스레드 중 대다수가 실제 작업을 수행하지 못하고 DB 리소스를 기다리는 상태에 있었습니다.
DB Connection Pool 분석
HikariCP의 기본 커넥션 풀 크기는 50개로 설정되어 있습니다.

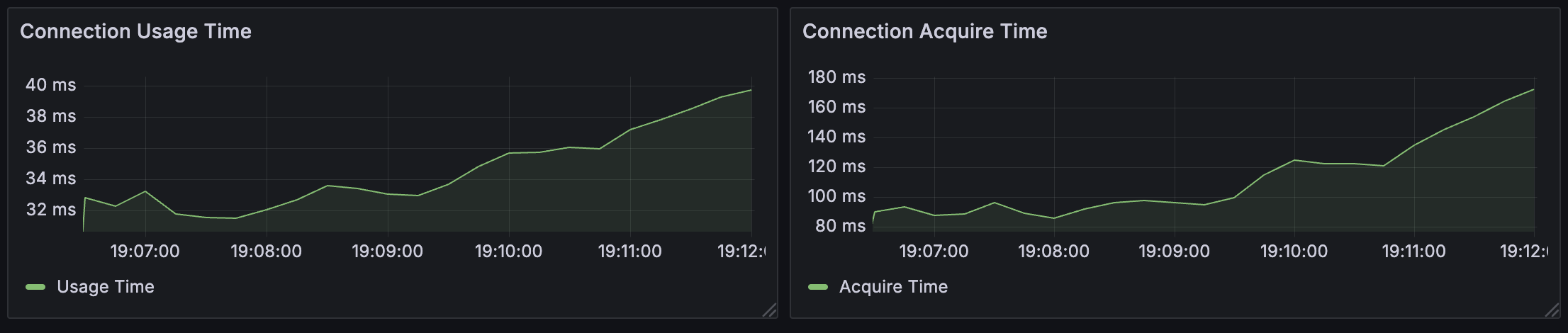
- 활성 커넥션 수 : 최대값인 50개에 도달하여 완전히 포화 상태 유지
- Pending 커넥션 수 : 최대 349개까지 증가 (400개 스레드 중 349개가 DB 커넥션을 기다리고 있다는 의미)
- 커넥션 획득 시간(Acquire Time) : 초기 80ms에서 시간이 지날수록 최대 180ms까지 증가
- 커넥션 획득 시간(Usage Time) : 초기 30ms에서 약 40ms까지 증가
가장 중요한 지표는 커넥션 획득 시간(180ms)이 실제 사용 시간(40ms)보다 4.5배 길다는 점입니다.
커넥션 획득 대기 비율 = 180ms / (180ms + 40ms) ≈ 82%
실제 DB 작업 비율 = 40ms / (180ms + 40ms) ≈ 18%이는 전체 DB 작업 시간의 82%가 단순히 커넥션을 기다리는 데 낭비되고 있음을 의미합니다.
DB Connection 사용 패턴 분석
// 중복 체크 (읽기 작업)
@Lock(LockModeType.PESSIMISTIC_WRITE)
boolean existsByPhoneNumber(String phoneNumber);
// 응모 데이터 저장 (쓰기 작업)
applyRepository.save(apply);이 패턴에서 가장 심각한 병목은 @Lock(LockModeType.PESSIMISTIC_WRITE) 어노테이션이 적용된 중복 체크 쿼리입니다.
이 어노테이션으로 인해 아래와 같은 SQL이 생성됩니다.
SELECT * FROM Apply WHERE phoneNumber = ? FOR UPDATE이 쿼리는 InnoDB 스토리지 엔진에서 Next-Key Lock을 획득하며
- 락 범위: 조회 조건에 해당하는 레코드뿐 아니라, 해당 인덱스 범위('갭')까지 락이 설정됨
- 락 유지 시간: 트랜잭션이 완료될 때까지(commit 또는 rollback) 락이 유지됨
- 락 유형: 배타적 락(Exclusive Lock)으로 다른 트랜잭션의 읽기와 쓰기 모두 차단
이러한 특성으로 인해 동시성 제어는 매우 효과적이지만 고부하 상황에서는 락 경합이 급증하면서 심각한 성능 저하가 발생합니다.
CPU 사용률 분석

CPU 사용률이 현저히 낮음에도 불구하고 시스템 성능이 저하되는 것은 CPU가 대부분의 시간을 I/O 작업(주로 DB 커넥션 획득과 락 획득)을 기다리며 유휴 상태로 보내고 있기 때문입니다.
이는 시스템이 계산 능력(CPU)의 한계가 아닌, I/O 작업의 병목(I/O-bound)으로 인해 성능 제약을 받고 있음을 명확하게 보여줍니다. CPU 성능을 높이는 것보다 I/O 작업(특히 DB 접근 방식)을 최적화하는 것이 성능 향상의 핵심 포인트임을 알 수 있습니다.
종합 분석 및 병목 식별
- 가장 심각한 문제로 DB 커넥션 풀 고갈 및 경합으로 50개 커넥션에 400개 스레드가 경쟁하는 상황과 Pessimistic Lock으로 인한 커넥션 점유 시간 증가로 인해 커넥션 획득 시간이 400ms까지 늘어나 시스템 처리량이 크게 감소했습니다.
- 비관적 락으로 인한 동시성 제한으로 JPA의
@Lock(LockModeType.PESSIMISTIC_WRITE)적용이 DB 작업의 직렬 실행을 유발해 병렬성이 크게 감소했고, 부하가 증가할수록 성능 저하가 더욱 심해졌습니다. - GC 부담 증가로 요청마다 많은 임시 객체가 생성되고 GC 주기가 짧아져 최대 7.2ms의 STW시간이 발생해 요청 처리에 지연을 가져왔습니다.
- 스레드 풀 고갈 문제로 400개 스레드 대부분이 DB 작업을 기다리며 블로킹 상태에 있어 추가 요청 처리가 제한되었고, 400개를 초과하는 동시 요청은 처리할 수 없는 상황이었습니다.
결론
Spring Boot와 MySQL만을 사용한 단순한 아키텍처로는 초당 1,666건의 요청과 정확한 100명 선발이라는 요구사항을 충족하기 어렵다는 것을 확인했습니다. 특히 DB 커넥션 풀 병목과 Pessimistic Lock으로 인한 성능 저하가 가장 큰 문제였습니다.
동시성 제어를 위해 사용한 Pessimistic Lock은 정확성을 높이는 데는 효과적이라고 생각했지만, 성능 측면에서도 큰 병목을 야기했습니다. 특히 고부하 상황에서는 락 획득을 위한 대기 시간이 급격히 증가하여 전체 시스템 성능을 저하시켰습니다.
시스템을 설계할 때 동시성 제어와 성능 간의 균형을 맞추는 것이 매우 중요하다는 교훈을 얻었습니다. 단순한 락 기반 접근법으로는 고성능과 정확성을 동시에 달성하기 어렵다는 현실을 직접 경험했습니다.
하지만, 이러한 단순 구현과 성능 분석, 그리고 시행착오 과정은 시스템의 한계를 명확히 파악하고, 어떤 부분을 개선해야 하는지 방향을 잡는 데 큰 도움이 되었습니다.
다음 편에서는 이번 분석을 통해 도출한 개선 방향을 바탕으로 Redis를 활용한 개선된 아키텍처와 그 결과에 대해 살펴보려고 합니다. 특히 Redis의 원자적 연산을 활용하여 어떻게 동시성 문제와 성능 병목을 동시에 해결했는지 다뤄보겠습니다.
Redis Stream을 적용한 선착순 이벤트 시스템 (2편)
Spring Boot + MySQL로 구현한 선착순 이벤트 시스템 (1편)“매일 오후 1시에 선착순 100명에게 도서를 증정하는 이벤트 시스템”을 개발하게 되었습니다. 처음엔 단순해 보였지만, 높은 동시성과 정
hyodeng.tistory.com
'프로젝트' 카테고리의 다른 글
| SQL 튜닝을 통한 API 성능 최적화 (2편) (0) | 2025.03.11 |
|---|---|
| 성장하는 서비스를 위한 DDD 기반 멀티 모듈 전환기 (0) | 2025.03.07 |
| Spring MVC의 진입점을 파고들어 개선한 JWT 토큰 처리 시스템 (0) | 2025.02.19 |
| JPA와 MySQL로 구현한 동시성 (0) | 2025.02.05 |
| SQL 튜닝을 통한 API 성능 최적화 (1편) (0) | 2025.01.12 |